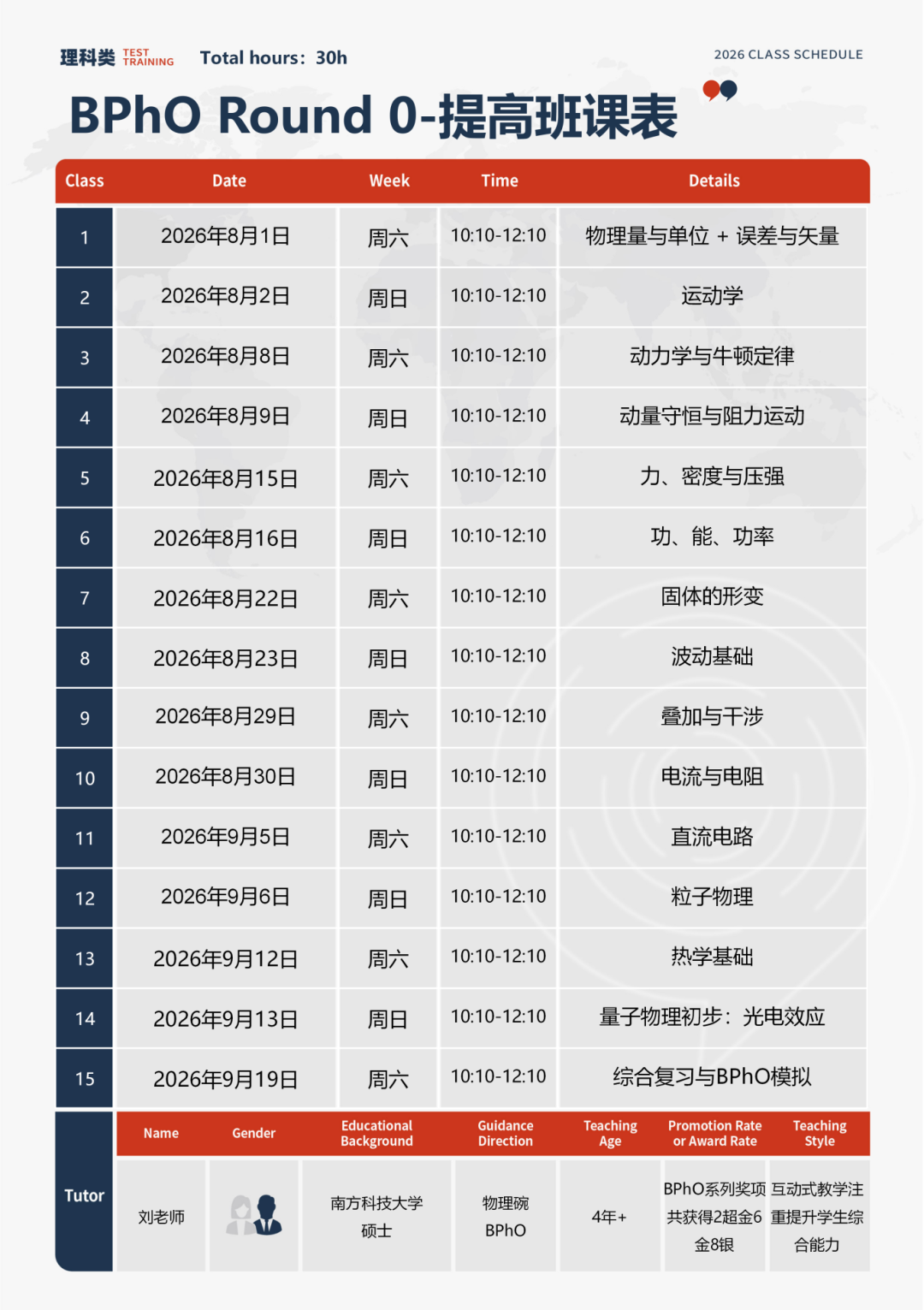
Kaggle Learning Equality - Curriculum Recommendations Top3 赛后分享!
赛题链接
https://www.kaggle.com/competitions/learning-equality-curriculum-recommendations
数据说明

- topic: 在本推荐问题中可以理解为 user
- content: 在本推荐问题中可以理解为 item
赛题任务基本可以理解为:为某个 topic 推荐相关度最高的若干个 content;也可以理解为从海量的 content 中检索出若干个与 topic 相关度最高的 content。
赛题难点
- 多语言文本
- 数据量较大
- bias 推荐问题,数据集中大部分 category == 'source' 的 topic 并不会出现在测试集中
最终名次
LB 3rd / PB 3rd

感谢四位极其出色及非常能肝的队友 @xiamaozi11 @syzong @sayoulala @yzheng21
其中 @syzong @sayoulala 为 Zlab 成员,欢迎大家关注 「Z Lab数据实验室」 公众号。
我们的代码将由 @syzong 整理后在「Z Lab数据实验室」 公众号上发布。
以下是我们的赛后 solution write-up。
提纲
- CV 策略
- 召回阶段
- 排序阶段
- 阈值处理
- 后处理
- 模型融合
训练 pipeline

CV 策略
我们随机从 topics.csv 里采样了 4000 个 category != 'source' 的 topic 作为 holdout set,这部分 topics 在所有训练过程中都不参与其中,仅作为验证集使用。这个简单的 CV 策略在除了后期融合阶段外的整个比赛过程,线上线下相当一致。
在比赛的最后一个月,我们将 4000 个 topic 再从中采样出来 1000 个 topic 作为验证集,单模提交时线上下 gap 还是相当稳定的,但在融合阶段,随着加入的模型越来越多,失去了一致性,导致我们在最后十一天里没有得到任何提升。
召回阶段
我们使用了 SimCSE (Simple Contrastive Learning of Sentence Embeddings: https://github.com/princeton-nlp/SimCSE) 对比学习来训练召回模型。

- 只使用正样本构建输入对
- 验证集需要从相同语言中随机采样一定的负样本来构建
- content 文本输入格式: title [SEP] kind [SEP] description [SED] text, maxlen = 256 (string level)
- topic 文本输入格式: title [SEP] channel [SEP] category [SEP] level [SEP] language [SEP] description [SEP] context [SEP] parent_description [SEP] children_description, maxlen = 256 (string level)
- simcse_loss
def simcse_loss(feature_topic, feature_content) -> 'tensor': y_true = torch.arange(0, feature_topic.size(0), device=device) sim = F.cosine_similarity(feature_topic.unsqueeze(1), feature_content.unsqueeze(0), dim=2) sim = sim / 0.05 loss = F.cross_entropy(sim, y_true) loss = torch.mean(loss) return lossfrom: https://github.com/yangjianxin1/SimCSE/blob/master/model.py
- 训练代码
for step, (inputs_topic, inputs_content, labels) in enumerate(train_loader):
inputs_topic = collate(inputs_topic)
for k, v in inputs_topic.items():
inputs_topic[k] = v.to(device)
inputs_content = collate(inputs_content)
for k, v in inputs_content.items():
inputs_content[k] = v.to(device)
batch_size = labels.size(0)
with torch.cuda.amp.autocast(enabled=CFG.apex):
feature_topic = model(inputs_topic)
feature_content = model(inputs_content)
loss = simcse_unsup_loss(feature_topic, feature_content)
召回指标 (1000 topic 验证集)
model F2@5 max positive score top50 max positive score top100 paraphrase-multilingual-mpnet-base-v2 0.5250 0.9135 0.9443 all-MiniLM-L6-v2 0.4879 0.9045 0.9353 mdeberta-v3-base 0.4689 0.8938 0.9187
执行召回时,我们计算了每一个 topic 跟本语言内所有 content 的 cosine similarity,然后选取 topN 个候选。
我们也尝试了通过带有权重的 cosine similarty 融合来进行三个召回模型的集成,虽然线下的 max positive score@50 提升到 0.9235,但是很奇怪,线上并没有得到提升,所以最终我们还是用了单模的 paraphrase-multilingual-mpnet-base-v2 用作召回。
排序阶段
排序模型基本上就是个文本二分类模型。
- 数据集构建:使用召回阶段用 SimCSE 训练好的模型对训练集数据执行召回 top100 个候选集,同时我们也添加了没有命中到的所有正样本。
- 文本处理:与召回阶段一致,最后构建语句对,格式:topic [SEP] content
- hard negative 样本能极大提升排序模型的性能。
retrieve model (max positive score top100) ranker f2 score (LB) 0.80 0.585 0.94 0.688
- 权重加载方式,可以用 huggingface 原生模型权重,也可以用经过召回阶段用 SimCSE 微调过的权重,两者相差并不大,但后者稍微好点且收敛明显较快。
- FGM, EMA 等通用的 trick 在本比赛中依然能发挥较大的提升作用,能提升 0.01,但 FGM 训练时间翻倍。
部分模型指标:
model validation (1,000 topics) LB score PB score mdeberta-v3-base (simcse weights, FGM+EMA) 0.7149 0.688 0.727 mdeberta-v3-base 0.6378 0.669 0.693
阈值处理
基本上完全依赖线下 1000 个验证 topic,循环计算各个阈值的 score,使用最优 score 的阈值,同时限制了最大的召回个数 (避免取的候选太多)。
best_thres = 0.
best_score = 0.
best_n_rec = 10
for thres in tqdm(np.arange(0.01, 0.2, 0.005)):
for n_rec in range(30, 50):
test_sub = test_data[test_data['score'] >= thres].reset_index(drop=True)
sub_df = test_sub.groupby('topic_id').apply(lambda g: g.head(n_rec)).reset_index(drop=True)
score = calc_f2(sub_df, label_df)
if score > best_score:
best_score = score
best_thres = thres
best_n_rec = n_rec
后处理
由于我们只是使用了一个阈值来划分是否取候选,会导致有部分 topic 完全没有候选 content 的情况。
这部分我们后处理应该还有提升的空间,我们最终的方案只是将这部分 topic 原来召回的 content 取 top4 填充回去。
尝试过的其他方式:
- 不同语言使用不同的阈值,线上线下都轻微掉分;
- 对这部分 topic 召回更多个数的 content (按我的理解是极有可能没有召回到正样本,毕竟召回命中率也没有 100%),再进行排序,线下明显提升了 0.005,但线上并没有得到提升。
模型融合
我们训练了二十来个模型,基于 不同的召回数/加载原生权重还是 SimCSE 微调权重/是否加FGM 等。
- mdeberta (simcse weights, 4,000 validate topics)
- mdeberta (simcse weights, 4,000 validate topics, with FGM,EMA)
- mdeberta (simcse weights, 1,000 validate topics)
- mdeberta (simcse weights, 1,000 validate topics, with FGM,EMA)
- mdeberta (1,000 validate topics, with FGM,EMA)
- xlm-roberta-large (simcse weights, 1,000 validate topics, with FGM,EMA)
- xlm-roberta-base (simcse weights, 1,000 validate topics, with FGM,EMA)
模型融合权重的确定:用 LR 来拟合验证集 prob,将 LR 的 coef_ 作为融合的权重
pcols = [c for c in valid_data.columns if c.startswith('score')]
for cols in tqdm([i for i in combinations(pcols, 10)]):
cols = list(cols)
X = valid_data[cols].values
y = valid_data['label'].values
lr = LinearRegression().fit(X, y)
coef = lr.coef_
print(get_score(valid_data, df_target_metric, cols, coef))
一开始我们是使用了召回数 100 来做融合,由于提交时长限制,最多只能融合 6 个模型,所以尝试了将召回数改为 70 或者 50,用来融合更多的模型。
number of recall samples per topic models validation (1,000 topics) LB score PB score 100 6 0.725 0.705 0.738 70 10 0.738 0.714 0.749 50 12 0.743 0.715 0.751